
Git-flow o anti-pattern mais querido da galera
O Git-flow se tornou bastante popular nos últimos anos como uma forma de organizar o fluxo de trabalho no desenvolvimento de software, usando uma das mais versáteis características do git: branchs. No entanto, não existe bala de prata. E o git-flow vem se mostrando uma solução over engineered, e, do meu ponto de vista, um anti-pattern. Vamos entender o por que e conhecer uma alternativa mais eficiente.
Problemas do Git-flow
Um problema que me faz não gostar do git-flow é o fato do histórico se tornar uma macarronada impossível de se gerenciar.

O histórico do controle de versão é justamente a motivação para se usar um versionador de código. Tornar o histórico ilegível faz com que o ato de versionar o código não faça sentido. Além do que, um histórico complicado de ler dificulta o revert de features. O git-flow não escala bem, quanto maior o time, pior fica.
No git-flow, geralmente é criada uma branch develop. Essa branch normalmente é uma branch que recebe os merges das feature branches. Todo commit da branch master vem de develop e para todo merge na master é criada uma tag. Mas a branch develop torna a branch master irrelevante. Cara, você tem toda a informação de que você precisa na develop e nas tags. Você poderia criar a release a partir de develop usando a tag. Pra que existe a branch master?
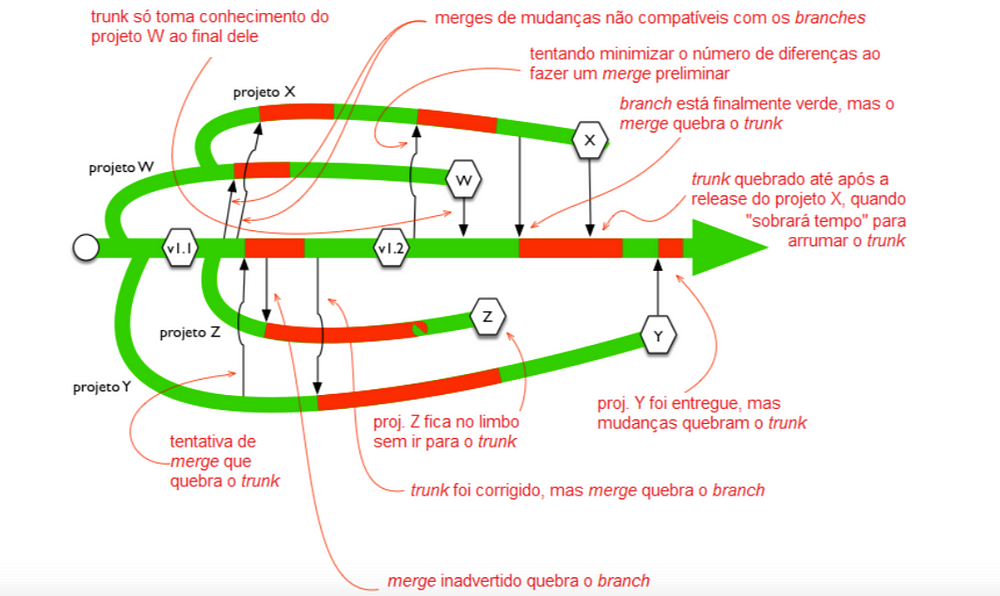
Aí, entramos na cereja do bolo dos problemas do git-flow: a complexidade desnecessária que o esse fluxo gera na gestão do ciclo de vida do software. O git-flow favorece a criação de branchs de longa duração, causando os famigerados merges hell. A perda de tempo gerenciando merges causa atrasos na entrega e possíveis erros podem passar despercebidos devido conflitos lógicos resolvidos automaticamente pelo git.
Continuos delivery? Ta de brincadeira né? Se usar git-flow, esqueça lean software development. Qualquer funcionalidade que não está em produção é custo. Durante o tempo em que se fica sem realizar merges, o custo do projeto cresce exponencialmente.
Solução? Sim. Contrate alguém para gerenciar o git-flow (Merge monkey) e mude o nome do seu controle de versão para subversion ou CVS. Brinks, vamos à solução.
Uma Única Fucking branch
O uso de branches é uma maneira pobre de estruturar um sistema, já que, em vez de desenvolver um sistema em que seja fácil adicionar e remover funcionalidades, isso é feito com merges manuais através do controle de versões
Dan Bodart
O git não é uma ferramenta fácil nem intuitiva. Seu time deve, primeiramente aprender a usá-lo. Após isso, seu time deve conhecer as boas práticas. E uma prática que ajuda muito no gerenciamento do repositório de código é criar commits pequenos, autônomos e com mudanças lógicas simples.
A branch principal, ou trunk, é a master. Só ela é relevante. Crie feature branches de curta duração a partir da master.
$ git checkout -b feature/my-feature master
A feature branch pode existir somente na máquina do desenvolvedor, mas se seu time usa pull requests para code review, pode-se fazer push da branch. Enquanto isso, a master pode estar sendo atualizada. É uma boa prática manter a feature branch sempre atualizada com o trunk. A primeira opção é usar rebase.
$ git checkout feature/my-feature$ git rebase -i master
O rebase deixa o histórico limpo e de fácil leitura. Essa estratégia é mais adequada para branchs recentes, caso contrário é melhor usar merge ao invés de rebase.
Ferramentas como o github já fazem merge usando --no-ff após a aprovação do pull request, mas caso não use uma ferramenta gráfica, o comando seria:
$ git checkout master$ git merge --no-ff feature/my-feature $ git push origin master
Criar um commit de merge usando --no-ff ajuda a realizar possíveis reverts, no entanto, deixa o histórico um pouco sujo. Você pode optar por realizar o merge com fast-foward mesmo.
Após o merge, não há mais motivo para a existência da feature branch, como um Meeseeks do Rick and Morty.
$ git branch -d feature/my-feature $ git push origin :feature/my-feature
A branch release é criada a partir de um commit da master. Caso seu time possua um processo de QA, é nessa branch que serão realizados os testes.
$ git checkout -b release/2.5.0 52f19a7
Após a release estiver ok, ela deve ser tagueada e versionada permanentemente na master.
$ git checkout release/2.5.0 $ git tag 2.5.0 $ git checkout master $ git merge release/2.5.0 $ git push --tags origin master
A branch release também é um meeseks e deve ser destruída após seu propósito ser cumprido.
$ git push origin :release/2.5.0
Em muitos casos teremos na branch master, features que não deveriam ir para a release. E agora? A primeira solução que pode vir à cabeça é usar chery-pick para criar a branch release. O problema é que cherry-pick dá trabalho e muitos, inclusive eu, o consideram um anti-pattern.
Nenhuma ferramenta ou método vai lhe salvar se você tiver um processo ruim. Depender somente do git para gerenciar o processo de release faz com que muitos times caiam no caos. Seu processo lean precisa estar bem definido. Por que uma funcionalidade estaria no trunk se não vai pra release? Quanto tempo foi desperdiçado para se criar código que não vai pra produção?
Mas caso seja necessário criar código que seu usuário não vai usar, existe a opção de usar feature flags ou features toggles.
Conclusão
Existem inúmeras formas de branching model além do git-flow. O citado acima é o que mais me agrada. Devemos usar a ferramenta certa para o contexto certo e nunca usar processos e métodos cegamente porque alguém disse que funciona.
Até a próxima.
Texto Original em https://medium.com/@paulociecomp/pare-de-usar-o-git-flow-6efc6a287094




2 Comentários
Gustavo Lobato
Concordo que o git-flow não é um fluxo adequado quando em um projeto busca-se entrega/deploy contínuo. Porém, faltou considerar que ainda tem muito legado e cenário que exige release planejada, de semanas ou até meses. É nesse cenário que o git-flow faz sentido. Ter uma branch de ‘release’ que receberá todo o código já testado e aprovado para entrar na próxima versão (nem todo código pronto já pode ir pra produção imediatamente, muitas vezes um lançamento envolve outras áreas, como CS, marketing…), uma branch ‘develop’ que conterá todo o código atual de desenvolvimento (evita retenção de código que não deveria entrar na próxima release), a branch ‘master’ com o código atual de produção e as temporárias ‘bugfix’, que precisam ser lançadas imediatamente. Enfim, cenários complexos podem exigir versionamento mais complexo e, nesse caso, usar um modelo pré-estabelecido pode ser mais simples que usar apenas uma branch.
Arthur
Concordo com o Gustavo Lobato, o git-flow tem seu caso de uso, na vida real a maioria dos projetos precisam passar antes por uma branch de release antes de entrarem para master, só faz sentido um novo método de branching se ele seja aplicável em cenários da vida real, com disse o Gustavo, na vida real precisamos homologar releases com diversas outras áreas e interagir com diversas outras equipes de desenvolvimento, portanto, o modelo proposto por esse artigo também é um anti-pattern pois inviabiliza o controle do que vai ou não para o release para ser homologado por outras áreas ou que vá entrar para outras equipe de desenvolvimento.